BIG Data with Microsoft
HD Insight is the Hadoop big-data framework which works on the Windows Azure technology. Microsoft has developed this application in partnership with Horton works which is aimed at helping the user to handle large amounts of data across all clusters. Making this framework available in the cloud, users can rotate the Hadoop Clusters up and down when ever they need. HDInsight has powerful programming extensions for languages including, C#, Java, .NET and more.It is also integrated with Hortonworks Data Platform, so that you can move Hadoop data from an on-site data centre to the Azure cloud for backup, development or test and for cloud bursting scenarios.
HD Insights important features include:
HD Insights important features include:
- The Hadoop distributed File System (HDFS) facilitates the storage of huge volumes of data. It reduces the difficulties that are usually involved in extracting large amount of unstructured data from various sources.
- The MapReduce application helps in analyzing and extracting results from the data and interprets the data in terms of key-value pairs.
- HD Insights is embedded with simplified JavaScript that enables developers to deal with big data processing.
- HD Insights provides Open Data Base Connectivity (ODBC) to combine other business tools such as SQL server analysis and MS Excel.
- Simple and effective management of huge volumes of data.
- Secure and enterprise ready Apache Hadoop based application.
- Open source of Hadoop is available on Windows which makes it easily compatible with same.
- Augment the existing Javascript applications.
He(alth)doop !
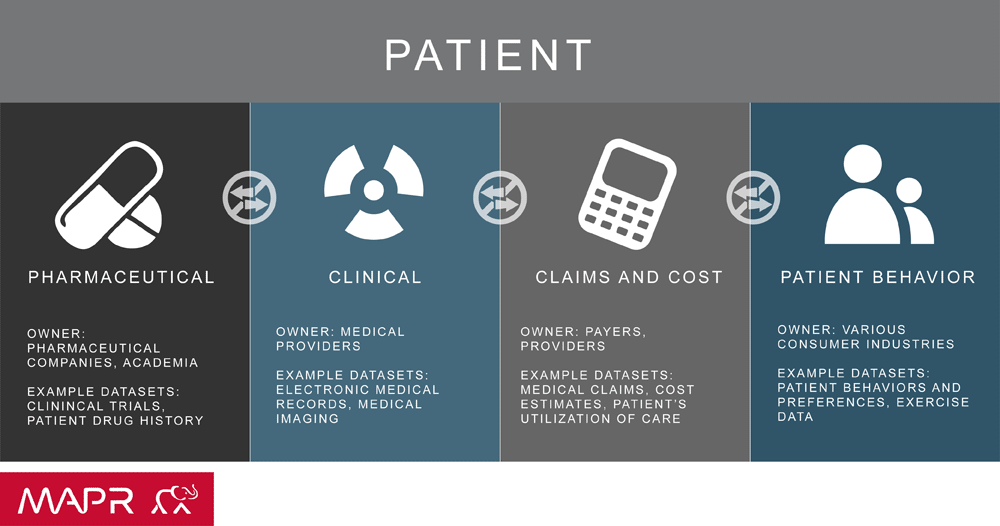
Today, making use of big data has become a norm in various industries and business sectors. The healthcare industry is no exception. In particular, medical facilities, which generate and process huge volumes of medical information and medical device data, have been accelerating big data utilization.
As technology evolves and electronic data becomes more complex, digital medical record management and analysis becomes a challenge. In order to discover patterns and make relevant predictions based on large data sets, researchers and medical professionals must find new methods to analyze and extract relevant health information.With the effective use of big data, healthcare organizations ranging from single-physician offices and multi-provider groups to large hospital networks and accountable care organizations stand to realize significant benefits. Potential benefits include detecting diseases at earlier stages when they can be treated more easily and effectively; managing specific individual and population health and detecting health care fraud more quickly and efficiently.
Using analytics to gain better insights can help demonstrate value and achieve better outcomes, such as new treatments and technologies. Information leading to insight can help informed and educated consumers become more accountable for their own health.
Our analytics platform unlocks the wealth of knowledge from patient electronic health records and provides actionable solutions to help clinicians be more effective and improve patient outcomes. We’ve taken our expertise in engineering and data analytics and applied it to health care to mine data and perform analytics on it – offering tremendous benefits in the clinical space.
As technology evolves and electronic data becomes more complex, digital medical record management and analysis becomes a challenge. In order to discover patterns and make relevant predictions based on large data sets, researchers and medical professionals must find new methods to analyze and extract relevant health information.With the effective use of big data, healthcare organizations ranging from single-physician offices and multi-provider groups to large hospital networks and accountable care organizations stand to realize significant benefits. Potential benefits include detecting diseases at earlier stages when they can be treated more easily and effectively; managing specific individual and population health and detecting health care fraud more quickly and efficiently.
Using analytics to gain better insights can help demonstrate value and achieve better outcomes, such as new treatments and technologies. Information leading to insight can help informed and educated consumers become more accountable for their own health.
Our analytics platform unlocks the wealth of knowledge from patient electronic health records and provides actionable solutions to help clinicians be more effective and improve patient outcomes. We’ve taken our expertise in engineering and data analytics and applied it to health care to mine data and perform analytics on it – offering tremendous benefits in the clinical space.
Banking on BIGDATA

Banks have plenty of data from ATMs, websites, phone calls, emails, and mobile transactions, but have done little to leverage it. All of this data can be linked back to the individual customers and that's where the power of individual-level marketing comes in. By getting this data out of individual silos and mining it, banks can better anticipate what customers are trying to do and personalize their experience. Banks need to organize the knowledge they have about their customers, aggregate it, make effective use of customer data from multiple sources, and then act on it. Using big data and prediction to analyze and better understand customers allow banks to understand their customers and make the right offer at the right time to the right customer.
Banks can also utilize the massive amounts of data on their customers and predict to introduce new offerings that target predefined segments based on location, demographics, psychographics, and other factors while also increasing revenues and deepening customer relationships. Banks internationally are beginning to harness the power of data in order to derive utility across various spheres of their functioning, ranging from sentiment analysis, product cross selling, regulatory compliances management, reputational risk management, financial crime management and much more. Banks are increasingly embracing the new world of big data and analytics, serving as a bellwether for other consumer-facing industries eager to similarly create a definitive single view of each customer, serve and retain them, attract additional business, better manage risk and mine new revenue streams.
Kreara Analytics Suite is the most comprehensive business analytics tool for today’s decision makers. It provides a 360 degree view of the organization’s performance and empowers users with critical insights into the Key Performance Indicators (KPI) that can ‘Measure, Monitor and Manage’ their business goals and growth.The BI Solution for banks covers the complete range of functional areas under Retail and Corporate Banking, viz: Loans, Deposits, Trade Finance, Financial Performance, Trade Finance, Treasury, Risk and Customer. The solution has dedicated modules for Products, Channels, Sales and Marketing as well.
Banks can also utilize the massive amounts of data on their customers and predict to introduce new offerings that target predefined segments based on location, demographics, psychographics, and other factors while also increasing revenues and deepening customer relationships. Banks internationally are beginning to harness the power of data in order to derive utility across various spheres of their functioning, ranging from sentiment analysis, product cross selling, regulatory compliances management, reputational risk management, financial crime management and much more. Banks are increasingly embracing the new world of big data and analytics, serving as a bellwether for other consumer-facing industries eager to similarly create a definitive single view of each customer, serve and retain them, attract additional business, better manage risk and mine new revenue streams.
Kreara Analytics Suite is the most comprehensive business analytics tool for today’s decision makers. It provides a 360 degree view of the organization’s performance and empowers users with critical insights into the Key Performance Indicators (KPI) that can ‘Measure, Monitor and Manage’ their business goals and growth.The BI Solution for banks covers the complete range of functional areas under Retail and Corporate Banking, viz: Loans, Deposits, Trade Finance, Financial Performance, Trade Finance, Treasury, Risk and Customer. The solution has dedicated modules for Products, Channels, Sales and Marketing as well.
BIG CONSTRUCTION

Running a profitable construction firm is a difficult business. Faced with an unprecedented number of external pressures such as eroding profit margins, higher owner expectations, rapidly changing technology, and a dwindling workforce, only contractors who follow best practices will achieve a higher return on investment and reduce their risk.
Big data analytics is being adopted at a rapid rate across every industry. It enables businesses to manage and analyze vast amounts of data at ultrafast speeds, and obtain valuable insights that can improve their decision-making processes.
One of the industries that are reaping the benefits of this technology is the construction industry. Construction companies are using big data to perform a wide range of tasks, from data management to pre-construction analysis. For the construction industry, volume and variety becomes particularly relevant. From project planning to the project close out, a lot of structured as well as unstructured data is being generated and recorded for each construction project. Examples of those data include daily work report, data generated from various sensors and equipment, images and videos of the construction site, etc. With the use of some of the big data technologies, useful insights can be obtained from these datasets. Larger the size of data, more accurate the predictions and conclusions drawn from it.
KREARA will leverage your data and drive better visibility across projects by providing insights and measuring key performance indicators such as: liquidity indicators, schedule variance indicators, committed cost indicators, backlog indicators, scorecard indicators and work-in-process reporting.
Our big data analytics can help you gain valuable insights that enable you to improve cost certainty, identify and avoid potential problems, and find opportunities for efficiency improvements.
Big data analytics is being adopted at a rapid rate across every industry. It enables businesses to manage and analyze vast amounts of data at ultrafast speeds, and obtain valuable insights that can improve their decision-making processes.
One of the industries that are reaping the benefits of this technology is the construction industry. Construction companies are using big data to perform a wide range of tasks, from data management to pre-construction analysis. For the construction industry, volume and variety becomes particularly relevant. From project planning to the project close out, a lot of structured as well as unstructured data is being generated and recorded for each construction project. Examples of those data include daily work report, data generated from various sensors and equipment, images and videos of the construction site, etc. With the use of some of the big data technologies, useful insights can be obtained from these datasets. Larger the size of data, more accurate the predictions and conclusions drawn from it.
KREARA will leverage your data and drive better visibility across projects by providing insights and measuring key performance indicators such as: liquidity indicators, schedule variance indicators, committed cost indicators, backlog indicators, scorecard indicators and work-in-process reporting.
Our big data analytics can help you gain valuable insights that enable you to improve cost certainty, identify and avoid potential problems, and find opportunities for efficiency improvements.
CASE STUDY: BIG DATA SEARCH
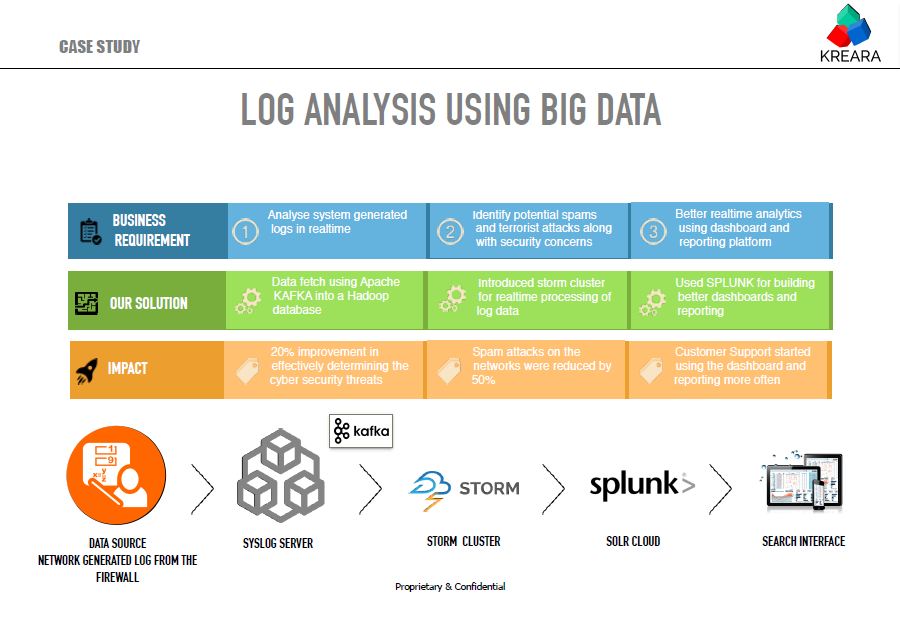
CASE STUDY: LOG ANALYSIS USING BIG DATA
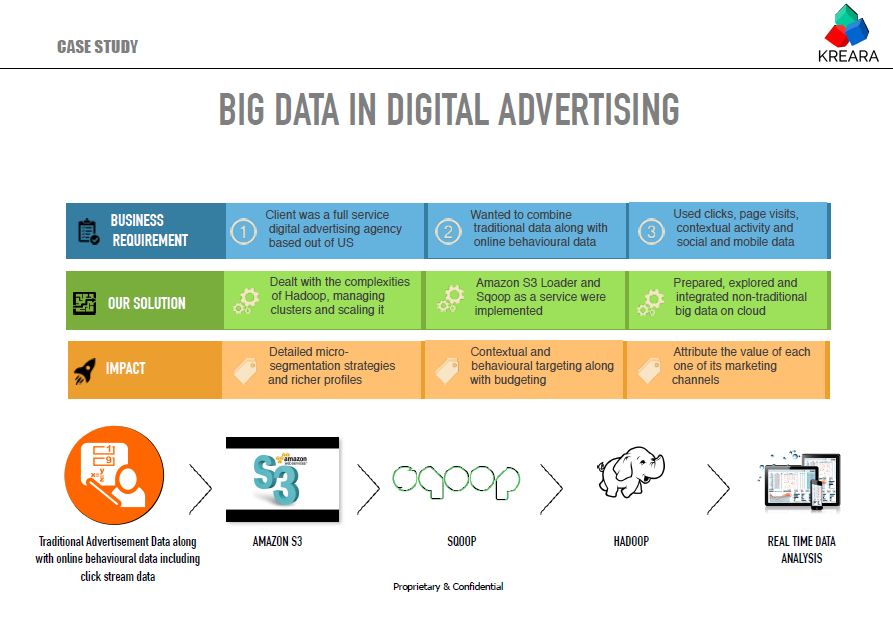
Case study: big data in digital advertising
BIG DATA
The new order of the internet accumulates data from multiple sources; They include Enterprise Databases, Social Media, Web and Sensory Devices that form part of the IOT paradigm. This gives rise to enormous amount of data that's growing in volume, variety, velocity & complexity. The data is coming in, paced like a fast and furious movie. Are your ready for this data explosion ? Do you have a a BIG DATA strategy to combine new and existing data sources, make better decisions and manage your enterprise ? Will your data turn out to be a burden or more value going forward ? Uncovering insights from this data requires effective aggregation, integration, validation and cleaning techniques. It extends beyond change of technology landscape to include analytical processes, methodologies and workflows aimed at generating the right insights that accelerate real time business value.
Kreara enables organizations conceptualise and drive a well thought out big data program across multiple domains and focus areas, which enable them to achieve the twin objectives of revenue maximization and increasing operational efficiency. On one hand, we enable organizations get the right customer insights leading to newer revenue sources through cross sell and upsell, and on the other, we help them plug revenue leakages and detect fraud thereby driving profitability. Through a comprehensive set of big data services and big data solutions straddling across the spectrum from big data consulting to support and managed services, we help you generate actionable insights from your big data initiatives.
At Kreara we will work with you to structure this data and put it in order. As a company which has been working in data analytics for the past 11 years, it was only a natural transition for us to venture into technologies and thought leadership which will augment your BIG DATA transition. We will help you carve out a big data strategy, put the necessary hardware, software and databases in place to implement that strategy and combine it with powerful analytics and visualisation tools to help you manage your enterprise in a fast and cost effective fashion. Some of the services that we offer in the big data space are depicted above
Kreara enables organizations conceptualise and drive a well thought out big data program across multiple domains and focus areas, which enable them to achieve the twin objectives of revenue maximization and increasing operational efficiency. On one hand, we enable organizations get the right customer insights leading to newer revenue sources through cross sell and upsell, and on the other, we help them plug revenue leakages and detect fraud thereby driving profitability. Through a comprehensive set of big data services and big data solutions straddling across the spectrum from big data consulting to support and managed services, we help you generate actionable insights from your big data initiatives.
At Kreara we will work with you to structure this data and put it in order. As a company which has been working in data analytics for the past 11 years, it was only a natural transition for us to venture into technologies and thought leadership which will augment your BIG DATA transition. We will help you carve out a big data strategy, put the necessary hardware, software and databases in place to implement that strategy and combine it with powerful analytics and visualisation tools to help you manage your enterprise in a fast and cost effective fashion. Some of the services that we offer in the big data space are depicted above

Data Lakes
Are you tired of spending millions of dollars on licenses and consultants for setting up your enterprise data ware house only to find out that your analysts are still using MS Excel to do their data analysis ? Have your heard about data lakes. Enterprises that must use enormous volumes and myriad varieties of data to respond to regulatory and competitive pressures are adopting data lakes. Data lakes are an emerging and powerful approach to the challenges of data integration as enterprises increase their exposure to mobile and cloud-based applications, the sensor-driven Internet of Things, and other aspects of the New IT paradigm.
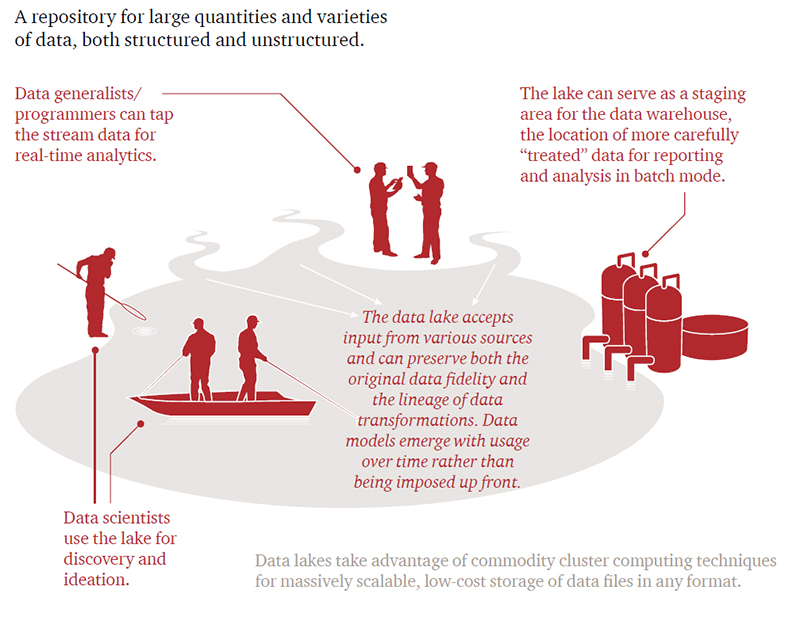
Data lakes can help resolve the nagging problem of accessibility and data integration. Using big data infrastructures, enterprises are starting to pull together increasing data volumes for analytics or simply to store for undetermined future use.Previous approaches to broad-based data integration have forced all users into a common predetermined schema, or data model. Unlike this monolithic view of a single enterprise-wide data model, the data lake relaxes standardization and defers modeling, resulting in a nearly unlimited potential for operational insight and data discovery. As data volumes, data variety, and metadata richness grow, so does the benefit.
Recent innovation is helping companies to collaboratively create models—or views—of the data and then manage incremental improvements to the metadata. Data scientists and business analysts using the newest lineage tracking tools such as Revelytix Loom or Apache Falcon can follow each other’s purpose-built data schemas. The lineage tracking metadata also is placed in the Hadoop Distributed File System (HDFS)—which stores pieces of files across a distributed cluster of servers in the cloud—where the metadata is accessible and can be collaboratively refined. Analytics drawn from the lake become increasingly valuable as the metadata describing different views of the data accumulates.
Every industry has a potential data lake use case. A data lake can be a way to gain more visibility or put an end to data silos. Many companies see data lakes as an opportunity to capture a 360-degree view of their customers or to analyze social media trends.In the financial services industry, where Dodd-Frank regulation is one impetus, an institution has begun centralizing multiple data warehouses into a repository comparable to a data lake, but one that standardizes on XML. The institution is moving reconciliation, settlement, and Dodd-Frank reporting to the new platform. In this case, the approach reduces integration overhead because data is communicated and stored in a standard yet flexible format suitable for less-structured data. The system also provides a consistent view of a customer across operational functions, business functions, and products.
Courtesy : PWC
Recent innovation is helping companies to collaboratively create models—or views—of the data and then manage incremental improvements to the metadata. Data scientists and business analysts using the newest lineage tracking tools such as Revelytix Loom or Apache Falcon can follow each other’s purpose-built data schemas. The lineage tracking metadata also is placed in the Hadoop Distributed File System (HDFS)—which stores pieces of files across a distributed cluster of servers in the cloud—where the metadata is accessible and can be collaboratively refined. Analytics drawn from the lake become increasingly valuable as the metadata describing different views of the data accumulates.
Every industry has a potential data lake use case. A data lake can be a way to gain more visibility or put an end to data silos. Many companies see data lakes as an opportunity to capture a 360-degree view of their customers or to analyze social media trends.In the financial services industry, where Dodd-Frank regulation is one impetus, an institution has begun centralizing multiple data warehouses into a repository comparable to a data lake, but one that standardizes on XML. The institution is moving reconciliation, settlement, and Dodd-Frank reporting to the new platform. In this case, the approach reduces integration overhead because data is communicated and stored in a standard yet flexible format suitable for less-structured data. The system also provides a consistent view of a customer across operational functions, business functions, and products.
Courtesy : PWC
BIG DATA IN CLINICAL TRIALS

Let us first list down what is possible by deploying a big data solution for the CT industry.
We will use predictive modeling of biological processes and drugs to accelerate computer aided drug discovery. Combining the molecular and clinical data, statistical tools will help the pharma companies to identify new potential-candidate molecules which could be developed as safe and efficacious drugs.
Enhanced patient enrollment combining the data from the PHR, EHR, Social Media, HIS and Mobile phone interactions. Powerful text mining and data mining engines could be developed to analyse these data sources and identify suitable candidates that meet the inclusion and exclusion criteria.
All trials are monitored real time to identify frauds, non compliances, adverse events etc on a near to realtime basis. Risk based monitoring could be enables.
Centralized data sources which will combine all the data related to multiple geographically distributed trials into a centralized data source.
Pharmaceutical companies have started investing significantly in improving big-data analytical capabilities. The road ahead is indeed challenging, but the big-data opportunity in pharmaceutical R&D is real, and the rewards will be great for companies that succeed.
We will use predictive modeling of biological processes and drugs to accelerate computer aided drug discovery. Combining the molecular and clinical data, statistical tools will help the pharma companies to identify new potential-candidate molecules which could be developed as safe and efficacious drugs.
Enhanced patient enrollment combining the data from the PHR, EHR, Social Media, HIS and Mobile phone interactions. Powerful text mining and data mining engines could be developed to analyse these data sources and identify suitable candidates that meet the inclusion and exclusion criteria.
All trials are monitored real time to identify frauds, non compliances, adverse events etc on a near to realtime basis. Risk based monitoring could be enables.
Centralized data sources which will combine all the data related to multiple geographically distributed trials into a centralized data source.
Pharmaceutical companies have started investing significantly in improving big-data analytical capabilities. The road ahead is indeed challenging, but the big-data opportunity in pharmaceutical R&D is real, and the rewards will be great for companies that succeed.
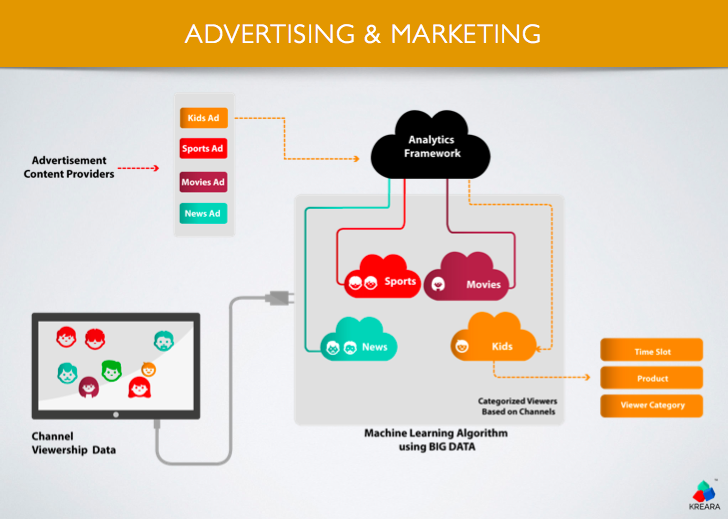
BIGDATA in Advertising
Advertising analytics revolves around three different areas, Attribution, Optimization and Allocation as depicted in the following diagram. Aggregating data sources from different platforms and using analytics to predict business outcomes, has been a core strength of Kreara.

We recently developed a platform on BIGDATA which will provide an analytics framework for a near realtime placement of an advertisement while ensuring the maximum returns.
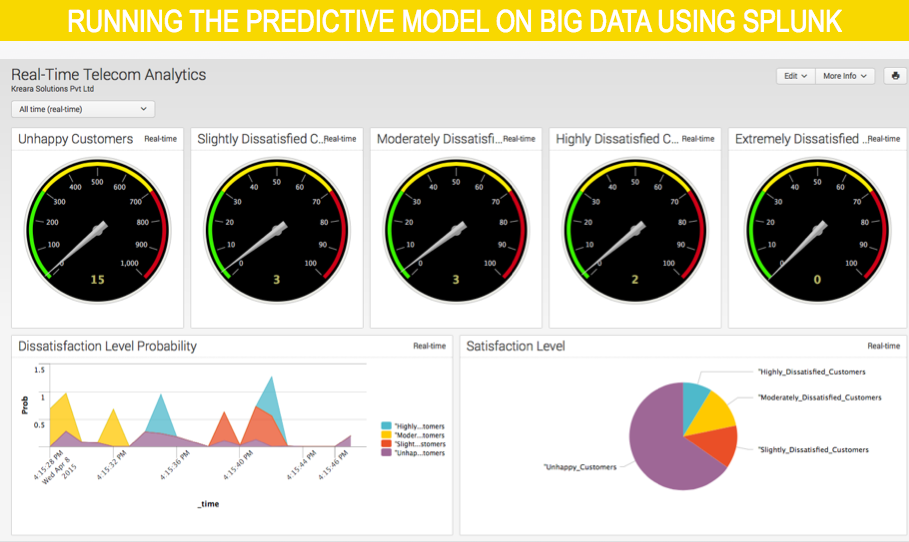
REALTIME TELECOM ANALYTICS USING SPLUNK
Splunk provides a unified way to organize and extract real-time insights from massive amounts of machine data from virtually any source. This includes data from websites, business applications, social media platforms, app servers, hypervisors, sensors, traditional databases and open-source data stores. Traditional business intelligence, data warehouse or IT analytics solutions are simply not engineered for this class of high-volume, dynamic and unstructured data. Hunk: Splunk Analytics for Hadoop and NoSQL Data Stores is a full-featured, integrated analytics platform that enables anyone in your organization to interactively explore, analyze and visualize raw, unstructured big data. Recently splunk was used to deploy a predictive model that was developed for a telecommunication service provider. This model will accept 5 different data sources in realtime and classify and assign customers to difference satisfaction levels.
Please find below the screen shots of the dashboard from SPLUNK.
Please find below the screen shots of the dashboard from SPLUNK.
CASE STUDY ON UNSTRUCTURED DATA ANALYSIS - BIGLOG
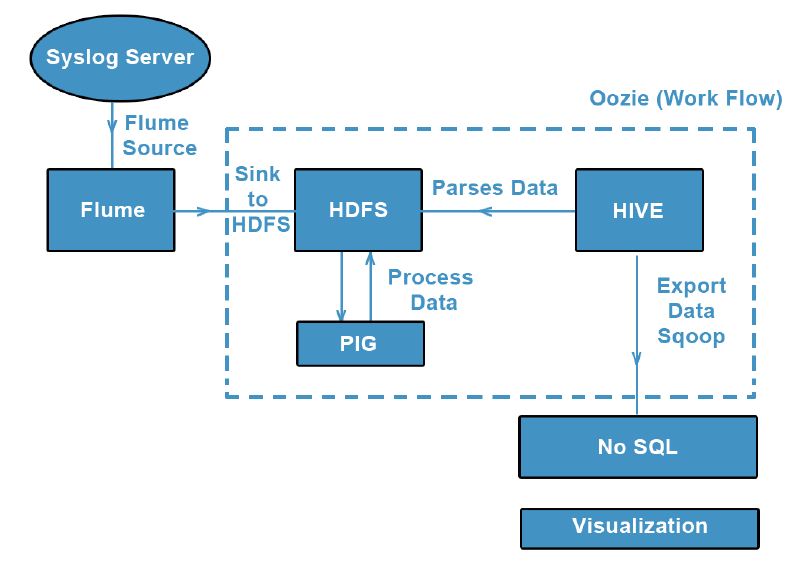
The analysis of system generated log data is very important in order to study the use of the data flow in an enterprise. It also plays a key role in terms of the hosted secured server environments. This will give an overall idea of the hit count on any URL and assess its impact. In this case study we analyzed system log files from KREARA (Router Generated Logs). Log files were plain text, unstructured files which contains list of url hits that occurred on the system server or any hosted application. These log files reside in the same system server. Each individual request is listed in a separate line as part of the log file and forms a log entry. Analysis of these log files provide the organization with insights that help us understand traffic patterns, user activity, user interests and much more. Flume was used to import real-time log data into HBASE and further analysis was done using the HADOOP
It will help to identify the following parameters from the log details as follows:
It will help to identify the following parameters from the log details as follows:
- Total Bandwidth usage per user, duration
- Total Request send per duration, user
- Websites most often visited by users
- Sessions of each users
BIG DATA IN CAPITAL MARKETS - NEVER TOO LATE
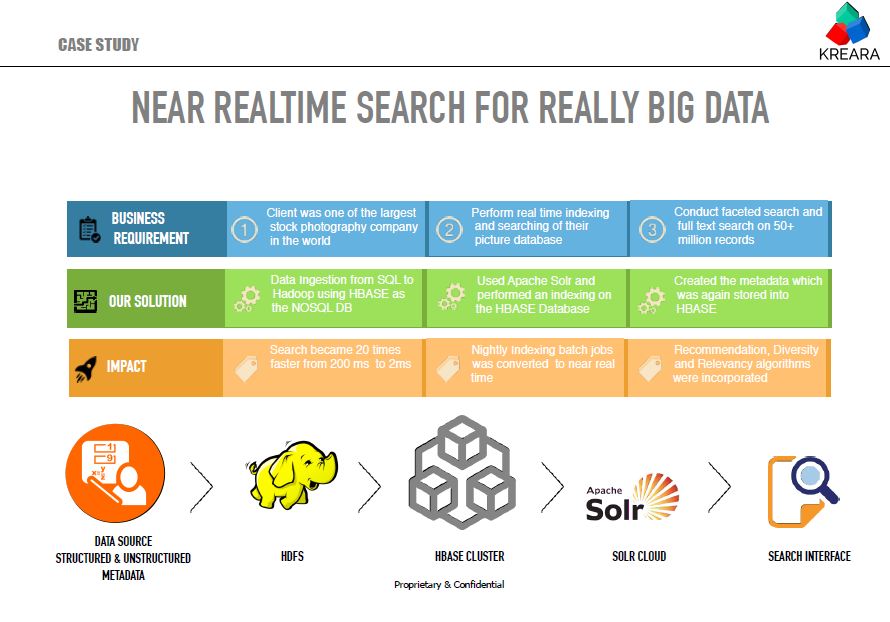
Stock market firms are transforming organically to handle the big data over years. This article discusses the key transformations that stock market firms are undergoing to handle big data along with the use of big data technologies in capital markets.
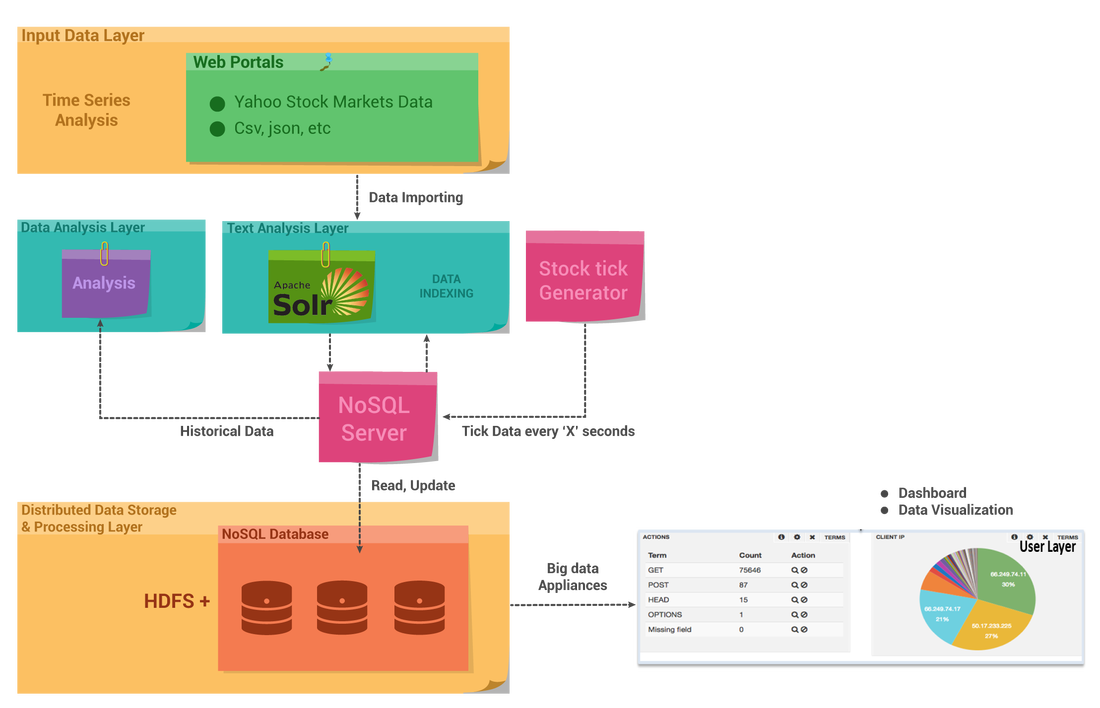
First the market data was downloaded from NASDAQ & NYSE using a Java API. The data was streamed real-time. The unstructured stock data from various sources including social media and news networks was also aggregated, structured and then processed to make sense out of it.
Solr Indexing and HDFS Integration:
The unstructured stock data was sent to Apache Solr for indexing. This is a highly capable open source search technology which makes it easy for organizations to enhance the speed of data access dramatically. With the 4.x line of Lucene and Solr, it's easier than ever to add scalable search capabilities to your data-driven applications. Also, Solr has got inbuilt support for writing and reading its own index and transaction log files to the HDFS distributed file system. This does not use Hadoop Map-Reduce to process Solr data; rather it only uses the HDFS file system for index and transaction log file storage.
The Hadoop Distributed File System (HDFS) is designed to run on commodity hardware. The structured stock data was also stored in HDFS
Data Visualization:
Banana is an open source dashboard and works with all kinds of time series (and non-time series) data stored in Apache Solr. The goal was to create a rich and flexible UI, enabling users to rapidly develop end-to-end applications that leverage the power of Apache Solr. Data can be ingested into Solr through a variety of ways like flume et al.
Conclusion:
Big Data technology implementation comes with its own cost. The 3 V’s of data (variety, volume & velocity) plays an extremely important role in the stock market. The Firms, who are still thinking of investing in Big Data technologies, should gear up soon before it becomes too late to remain competitive.
First the market data was downloaded from NASDAQ & NYSE using a Java API. The data was streamed real-time. The unstructured stock data from various sources including social media and news networks was also aggregated, structured and then processed to make sense out of it.
Solr Indexing and HDFS Integration:
The unstructured stock data was sent to Apache Solr for indexing. This is a highly capable open source search technology which makes it easy for organizations to enhance the speed of data access dramatically. With the 4.x line of Lucene and Solr, it's easier than ever to add scalable search capabilities to your data-driven applications. Also, Solr has got inbuilt support for writing and reading its own index and transaction log files to the HDFS distributed file system. This does not use Hadoop Map-Reduce to process Solr data; rather it only uses the HDFS file system for index and transaction log file storage.
The Hadoop Distributed File System (HDFS) is designed to run on commodity hardware. The structured stock data was also stored in HDFS
Data Visualization:
Banana is an open source dashboard and works with all kinds of time series (and non-time series) data stored in Apache Solr. The goal was to create a rich and flexible UI, enabling users to rapidly develop end-to-end applications that leverage the power of Apache Solr. Data can be ingested into Solr through a variety of ways like flume et al.
Conclusion:
Big Data technology implementation comes with its own cost. The 3 V’s of data (variety, volume & velocity) plays an extremely important role in the stock market. The Firms, who are still thinking of investing in Big Data technologies, should gear up soon before it becomes too late to remain competitive.
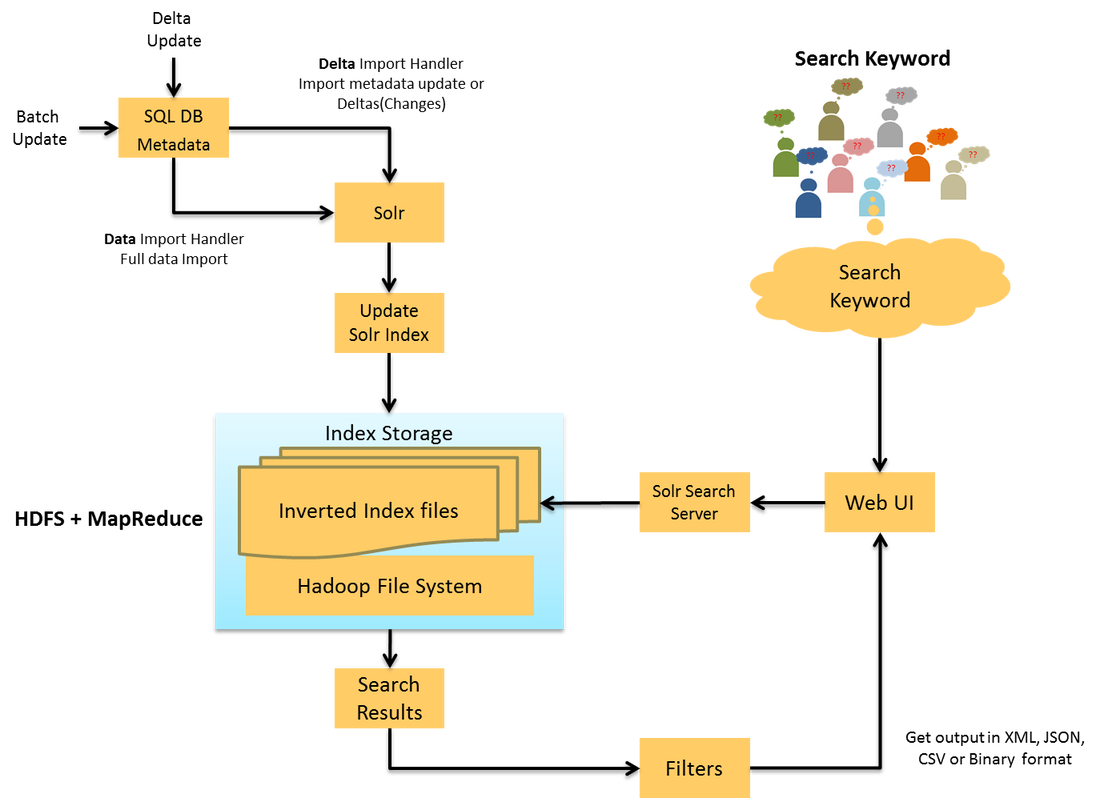
Big Data Search Using Solr & Hadoop
Recently, Kreara successfully implemented a solr based search server for one of our clients in UK. The existing search server was running on a home grown custom built search engine. During the initial days of the company the search engine scaled well with lesser number of datasets and few filters. As the data started to exponentially grow up to millions of records, the scalability and the caching started choking. It had become a hurdle in the search engine performance and the index caching.
Currently they have 50 million records which is residing in their search server and is expected to grow by 100 to 200 million records within the next couple of years. The search server was not sufficient enough to handle such scale up. It was decided that this issue could be resolved with the use of Solr Search Server. The indexing process was distributed into parallel nodes with redundant data using the power of Hadoop and MapReduce. The result was amazing. While the query time or the response time was 100-250ms with the old search engine, the solr search server was able to handle the same in 10-30ms without caching. This POC was done on a standalone search server
The advantages of the Big Data Search server using Solr and Hadoop includes
Currently they have 50 million records which is residing in their search server and is expected to grow by 100 to 200 million records within the next couple of years. The search server was not sufficient enough to handle such scale up. It was decided that this issue could be resolved with the use of Solr Search Server. The indexing process was distributed into parallel nodes with redundant data using the power of Hadoop and MapReduce. The result was amazing. While the query time or the response time was 100-250ms with the old search engine, the solr search server was able to handle the same in 10-30ms without caching. This POC was done on a standalone search server
The advantages of the Big Data Search server using Solr and Hadoop includes
- Power to scale out with the commodity hardware.
- Solr cloud will make its way easier and go faster.
- Solr search server can avoid the batch processing and manual intervention to update the indexes.
- Solr search server works on near real time.